Refining my mental model of vectors and cosine similarity
My mental model was that token embeddings represent points in n-dimensional space, and distance between points represents semantic similarity. Turns out that's not quite right.
The building block of the Transformer is the “vector”: an array of floats (numbers), like (0.1, 0.2, 0.3). Words or parts of words (“tokens”) are represented as a vectors, typically with dimensions 1 x n where n ranges from 768 to over 12,000. Every vector points to a location in n-dimensional space, and geometric relationships between vectors contain information about semantic relationships between the tokens they represent.
Here’s something new and important I just learned. As someone who’s taken geometry but not linear algebra, I have been mentally modeling a token vector (or “token embedding”, because we “embed” the token in vector space by representing it there) of n dimensions as a point coordinate in n-dimensional space. Just as (0,0) is the 2-D origin and (0,0,0) is the 3-D origin, we can use (0,…,0) vector of n length to represent the origin in n-D space. And I’ve basically been thinking of the length of the straight line that connects such points in high-D space (the “Euclidean distance”) as a measure of the similarity of meaning and usage (“semantic similarity”) between two tokens. But today I learned that this mental model is incorrect (or at least incomplete).
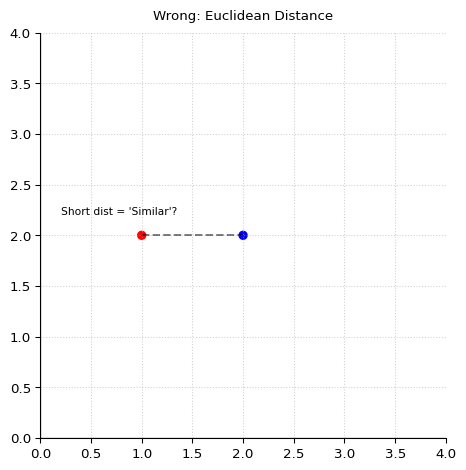
In the context of transformers, we should mentally model semantic embeddings as a ray extending outward from the origin and ending at the point coordinate defined by the vector. The angle between the two vectors measures the semantic similarity. Vectors that point in similar directions represent tokens with similar meaning or usage context (e.g., king and queen). When we do “cosine similarity search” during RAG (“retrieval augmented generation”), we are saying “let’s find the vector with the smallest angle (and thus greatest semantic similarity) to our search query. Euclidean distance between points is less informative for semantic similarity than the angle.
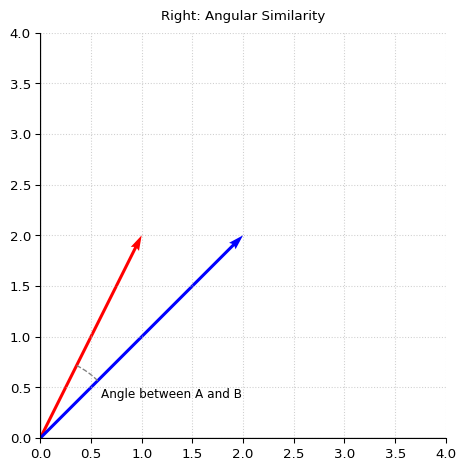
The angle is also closely related to the “dot product” of the two vectors (the sum of the products of the two sequences of numbers). In fact, for vectors of the same length (“magnitude”), the angle is the dot product. Which is why cosine similarity is measured by normalizing vector magnitudes to 1 and then computing dot product. Magnitude often represents certainty or importance of the token.
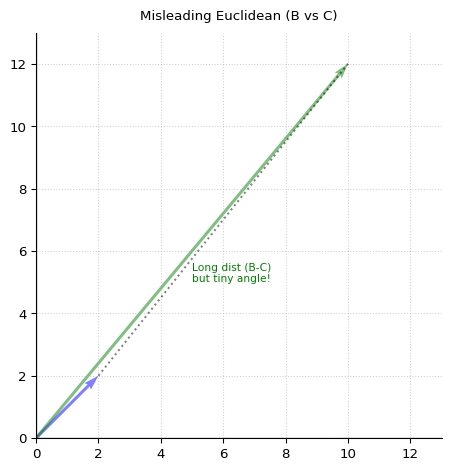
Because the magnitudes of A and B above are similar, they are closer by Euclidean distance than B and C below. But this is misleading. Because the angle between B and C is smaller, they are actually the more semantically similar vectors.